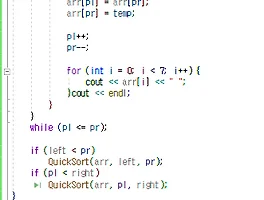
1. Solve the problem 34 and 40 in chapter 1
1.34
아래 중첩루프의 시간복잡도 T(n) ? (어떤 양의 정수 k에 대해서, n = 2^k)

i = n(2^k) 일때, j = i이므로 j =n(2^k) 이다. 따라서 두번째 while문은 한번 실행될 것이다.
그 후 i = i/2을 실행하여 i = 2^(k-1)이 된다.
다시 첫번째 while문으로 되돌아가 다시 실행이 되는데 이번에는 두번째 while문은 두 번 실행될 것이다.
이와 같은 과정을 첫번째 while문과 두번째 while문은 lgk번 반복될것이다.
따라서 Tout(lgk)*Tinner(lgk) = T(n) ==> lg²k 이다. 그러므로 T(n) = O(lg²n)이다.
1.40
f(n)과 g(n)은 점근적으로 양의 함수라고 가정하고 다음을 증명하시오.
(a) f(n) + g(n) ∈ O(max(f(n)),g(n))
O(큰 오)는 주어진 복잡도 함수 f(n)에 대해서 O(f(n))은 정수 N 이상의 모든 n에 대해서 다음 부등식이 성립하는 양의 실수 c와 음이 아닌 정수 N이 존재하는 복잡도 함수 g(n)의 집합이다.
g(n) <= c x f(n)
f(n) + g(n) <= 2*max(f(n), g(n)) 이다. 큰 O의 정의에서 c = 2와 N = 1을 취할 수 있으므로 f(n) + g(n) <= 2*max(f(n), g(n)) 이 성립한다. 따라서 f(n) + g(n) ∈ O(max(f(n)),g(n)) 이라는 결과가 나올 수 있다.
(b) f²(n) ∈ Ω(f(n))
Ω(오메가)는 주어진 복잡도 함수 f(n)에 대해서 Ω(f(n))은 N 이상의 모든 n에 대해서 다음 부등식을 만족하는 양의 실수 c와 음이 아닌 정수 이 존재하는 복잡도 함수 g(n)의 집합이다.
g(n) >= c x f(n)
정의에 의해서 N이상의 모든 정수 n에 대하여 다음 부등식이 성립하는 c와 N이 존재하는지 찾아보자. c=1, N=0이면 f²(n) >= f(n) 은 0 이상의 모든 n에 대하여 항상 성립한다.
따라서 f²(n) ∈ Ω(f(n)) 이다.
(c) f(n) + o(f(n)) ∈ ⊖(f(n)) , 여기서 o(f(n))란 g(n) ∈ o(f(n))을 만족하는 어떤 함수를 의미한다.
주어진 복잡도 함수 f(n)에 대해서 다음과 같이 정의한다.
⊖(f(n)) = O(f(n))∩Ω(f(n))
⊖(f(n))는 N 이상의 모든 정수 n에 대해서 다음 부등식이 만족하는 양의 실수 c,d와 음이 아닌 정수 N이 존재하는 복잡도 함수 g(n)의 집합이다.
c x f(n) <= g(n) <= d x f(n)
o(작은 오)는 주어진 복잡도 함수 f(n)에 대해서 o(f(n))은 모든 양의 실수 c에 대해서 n>=N을 만족하는 모든 n에 대해서 모든 n에 대해서 다음 부등식을 만족하는 음이 아닌 정수 N이 존재하는 모든 복잡도 함수 g(n)의 집합이다.
g(n) <= c x f(n)
g(n) ∈ o(f(n))이면 , g(n) ∈ O(f(n)) - Ω(f(n))이 성립한다. 즉, g(n)은 O(f(n))에는 속하지만, Ω(f(n))에는 속하지 않는다.
따라서 f(n) + o(f(n)) <= c*f(n)에서 c >= 2 ,N=0이면 f(n) + o(f(n))<=c*f(n)이 성립한다. 따라서 O(f(n))이 된다.
f(n) + o(f(n)) >= c*f(n)에서 c=1,N=0이면 f(n) + o(f(n))>=f(n)이 성립한다. 따라서 Ω(f(n))이 된다.
따라서 O(f(n))<=f(n)+o(f(n))<= Ω(f(n)) 이므로 f(n) + o(f(n)) ∈ ⊖(f(n))이다.
2. Apply sorting algorithms to the birthday dataset.
(a) prove correctness of each algorithm
(b) argue efficiency of each algorithm
permutation sort
(a)
permutation sort는 무지하게 많은 step을 필요로 한다. permutation sort는 볼 수 있는 가정의 수를 다 보기 때문이다.
생일 데이터를 가지고 permutation sort를 시행한다면 무작위로 작성된 97개의 생일데이터를 오름차순으로 배열하기 위해2^n 즉, 2^97개의 단계를 거치게 된다.
(b)
무작위로 작성된 생일 데이터(97)개를 읽는데 Ω(97!)가 걸린다.
생일 데이터가 오름차순으로 정렬되었는지 확인하는데 ⊖(97) 걸린다.
따라서 permutation sort는 총 Ω(97! * 97) 걸린다.
selection sort
(a)
selection sort는 무작위로 작성된 생일 데이터 중 가장 큰 데이터를 찾아 맨 마지막으로 이동시킨다. 그 후 이동시킨 데이터를 제외하고 남은 생일데이터를 비교하여 그 중 가장 큰 데이터를 찾아 마지막으로 이동시킨다. 가장 작은 데이터가 남을 때까지 이 과정을 반복한다. 각 단계를 거칠 때 마다 비교하는 숫자의 개수가 1개씩 줄어든다.
selection sort를 시행하여 생일데이터를 오름차순으로 배열하면, n-1 즉, 97-1 = 96의 단계를 거치게 될것이다.
(b)
정렬하려는 element가 1개일 경우 base라고 부르고 ⊖(1)값을 가진다.
n의 시간 복잡도를 S(n)이라고 하자. 한 단계를 실행할 때마다 비교하는 숫자의 개수가 1개 줄어드므로 n-1개의 시간 복잡도인 S(n-1)를 구할 수 있다. 비교한 데이터 중 가장 큰 데이터로 선택된 데이터는 비교되는 데이터 중 가장 마지막으로 이동되어야 한다. 또한 다음 단계를 실행할 때, 마지막으로 이동한 데이터는 더이상 비교하지 않으므로 ⊖(1)의 값을 가지게 된다.
그러므로 S(n) = S(n-1) + ⊖(1) 의 식으로 나타낼 수 있다.
S(n)을 cn이라고 하면, cn = c(n-1) + ⊖(1)이 되고 c = ⊖(1) 값을 가지게 된다
selection sort 의 시간복잡도는 S(n) = S(n-1) + ⊖(1)이므로 이를 계산하면, (n-1)+(n-2)+...+1 = n*(n-1)/2의 값이 나온다. 따라서 selection sort의 시간복잡도는 ⊖(n²)가 된다.